|
欢迎关注“创事记”微信订阅号:sinachuangshiji
文/Rex陈正翔
来源:微信公众号Rex陈正翔
跳船
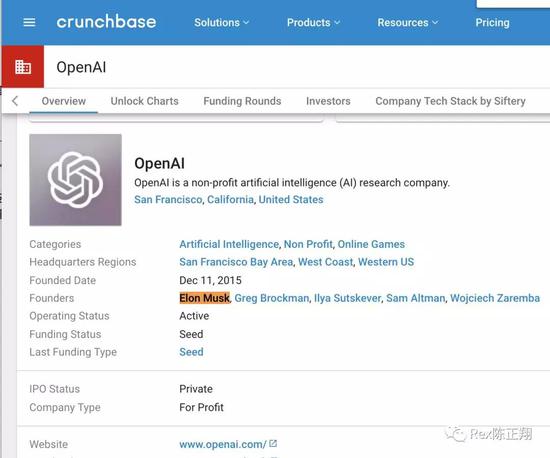
Sam Altman是谁?如果你是创业圈或者投资圈的,那你100%认识他。他就是美国大名鼎鼎的投资孵化器Y Combinator的CEO和联合创始人。
至于YC的战果我就不多废篇幅了,大家自行Google吧。大概也就800亿美金吧。
但是他今年3月宣布从YC辞职。加入OpenAI公司成为新的CEO。(但事实上他很早就参与了OpenAI的组建)
YC做得蒸蒸日上,公司做得好好的,为啥要离开?
很多人其实对OpenAI这个公司也是一知半解,多部分人脑海中的应该是一家“做打游戏的AI,天天叫嚣电竞选手”无所事事的公司。
Elon Musk马老板大家都不陌生,平时大家看到的新闻里他基本上都是带头反对AI的。但是OpenAI的创始人里面居然也有马老板的身影。这究竟是为啥?
带着这么多疑惑,刚好今年我花了蛮多时间在学习人工神经网络。我就分享一下这个恐怖故事。
如果有人从一艘游轮上跳到海里,那他一定看到了一艘火箭。
数据之争
OpenAI这个公司到底是干啥的?他们是搞【强化学习Reinforcement Learning】的。
emmmm,我尽量说人话。
人工智能目前大概有好几个功夫流派。监督学习,无监督学习,半监督学习。
通俗点的理解就是2类,有数据的 和 没数据的。
有数据的这一类比较常见,常用于各种图像识别。
比如需要识别图片中的人,需要先有大量的训练数据,靠人工标记好这张图里是否有人,人在画面里的坐标。当然高级一些的还需要标注好人的一些特征,比如男女,头发,表情这些。全靠人工。
如果你在共享办公室,那你一定见过突然隔壁公司有很多员工,而且每个人电脑画面差不多,然后干1个月全部被辞退的场景。那你隔壁一定有个AI公司。
目前在河南农村有很多这种数据标记村。市场价大概60元1万张。
所以这类AI公司一般也会说自己的优势啊就是数据。数据多么牛逼多么强无敌。事实上数据量和训练次数的边际成本极高。90~95%的准确率训练通常3~5万的数据就可以非常容易训练好。
但97%提高到98%,的数据代价是极其高昂的。而大部分使用场景下也并不差这1%的准确率。
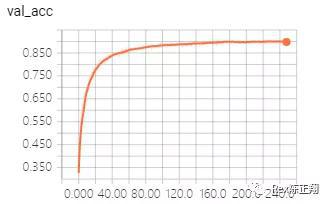 然而,在强化学习面前,数据根本没价值。 然而,在强化学习面前,数据根本没价值。 因为强化学习根本不需要数据。
强化学习的起源
2014年Google 4亿美金收购DeepMind,那Google为啥盯上了DeepMind?主要是因为2013年的这篇论文。
Playing Atari with Deep Reinforcement Learning
https://arxiv.org/abs/1312.5602
如果你懒得自己看,简单解释一下就是康奈尔大学在研究怎么用AI去玩最原始的游戏机。
 这款雅达利游戏机有很多很多游戏。(比我们玩的小霸王,FC更早一个时代) 这款雅达利游戏机有很多很多游戏。(比我们玩的小霸王,FC更早一个时代) 当时这套AI系统的设计诉求是
1.只写一套代码
(因为游戏很多,玩法也不同,所以不想每个游戏单独写一套算法去玩游戏。最好能通用所有游戏。)
2.不要准备数据
(同样因为游戏的玩法太多,如果人工准备训练数据,工程量也巨大。同时难以适应不同游戏。)
这套算法的原理具体细节大家可以看上面论文原文。我帮大家翻译一下人话。
原理如下:
1.让板子根据神经网络的控制来左右运动。(在没有训练的情况下基本上是乱抽搐)
2.如果板子接到了小球就奖励+10分。漏了就-10分。
3.如果板子靠近了小球就奖励1分。如果乱跑就-1分。
这样最初的神经网络结构是随机的,所以板子会毫无目的的乱抽搐乱动。
但由于奖励和惩罚机制的存在。行为会被不断修正。最终能完成任务。
如果你有小孩了,你应该瞬间可以理解这个过程。
因为基本算法基于Q-Learning的变种,于是这套依靠奖惩机制训练AI的方法也被叫做Deep Q-Learning Network缩写DQN。
这套方法其实代码量很少,很优雅。而且模型的收敛速度也很快。
不过这个游戏简单啊,只有2个Action(左移,右移)
小试牛刀
工程师们觉得这玩意牛皮啊,咱们实验室这么多显卡,算力大滴。要么咱玩个别的?
于是就有了AlphaGo和Dota还有星际2的吊打人类的AI。DeepMind和OpenAI。(两家基本算同行,都是强化学习流派)
如果说打Dota已经很难了,那么打星际2这种需要同时控制200个单位的游戏,每个兵种又有自己的技能。那才能体现出真正的实力。有兴趣的可以去看一下星际2的表现。
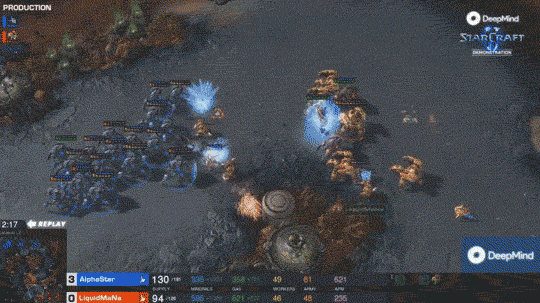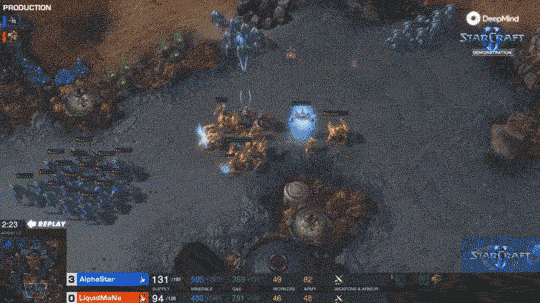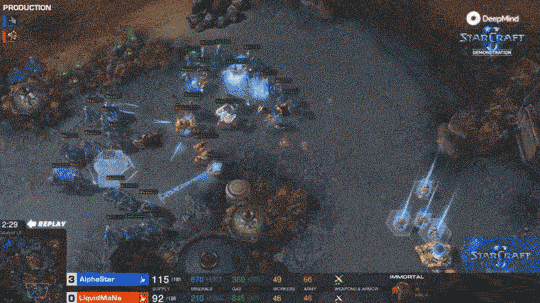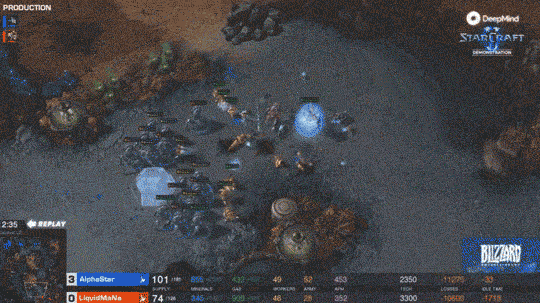 同时从3个方向进攻人类选手 同时从3个方向进攻人类选手 入侵现实
人类的本质就是作。既然强化学习能教AI自己学会做事情,那为啥不让它来控制真实世界的东西?
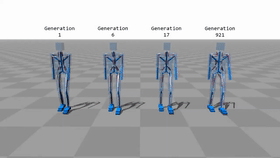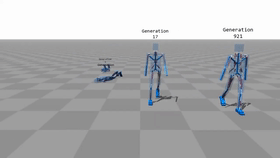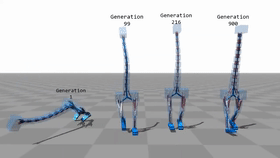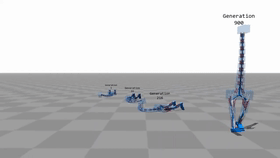
于是就有了最早的实验,让机器自己学会走路。
规则也特别简单,只要往前走就奖励+1分,原地磨蹭发呆-1分,走反了-2分。
 最皮的是即使不修改代码,更改腿的数量,神经网络也可以自动适应。 最皮的是即使不修改代码,更改腿的数量,神经网络也可以自动适应。 工程师一看,我擦嘞这也能玩?2个马达不够,给你多整几个。
于是就有了这个。大家自行感受一下。
 用神经网络进行的全肌肉模拟 用神经网络进行的全肌肉模拟 通过遗传算法进行优化后900代之后就可以正常运动。早期的版本都无法正常行走。
经过神经网络控制的肌肉运动对环境有很好的适应性,无论是障碍,外力,和坡度。
而我们的主角OpenAI呢,直接搞了一个机械手,一只手指4个马达,5个手指20个电机。
这个手的硬件基本上任何一个搞机械的公司都能造的出来。难点就在于软件太复杂了,程序写不来啊。
而OpenAI给这个机械手的第一个任务就是玩魔方!
你可以拿起你的手机,单手旋转这个手机。你可以感受一下你的手指同时有多少个肌肉在进行精密的配合。
20个电机的位置,转速,扭矩,怎么控制,怎么配合,怎么协调?头发掉光也不够啊!
如果是一整个胳膊,100个马达呢?1000个马达呢?
我们已经看到了一块人类智力无法企及之地
这种复杂度的任务,只有AI能替我们完成。
"推理"
如果刚才这些算是强化学习1.0
那么接下来的骚操作就是强化学习2.0了,要展开讲篇幅很大,我这里蜻蜓点水一下。有机会单独开篇再写。
要知道现实中很多任务并不是直接完成某一个动作就立刻有好的反馈。我们称之为「耐心」。
对于机器学习,结合长短期记忆LSTM (Long Short-Term Memory),可以完成更牛皮的任务。
比如推箱子。
这个任务看似简单。但背后有个极难跨越的瓶颈,就是跑到箱子的背后的方向的时候,箱子并没有更接近目的地,所以绕到箱子后面的过程不会有【实时的奖励】,跑回去的这个步骤事实上是为了【未来的收益】提前做的牺牲。(因为乱跑消耗体力也会惩罚)
这种策略式的记忆在1.0的思维里是无法完成的。
我们再来看另一个
这个任务里,要到达目标需要翻过一座墙,但是翻过墙的前提是需要踩着箱子过去,箱子要推过去才行。
而强化学习最恐怖的就是,整个这几套任务。代码并不需要修改。不同的环境可以被自动适应。
特斯拉汽车
该把马总请出来讲讲,天天在媒体上喊人类要小心AI,你自己为啥悄么声的投资了一家?还不只是股东还是联合创始人?
关注Tesla新闻的应该都知道,tesla工厂生产线隔三差五就停机,停工。然后一群人熬通宵。
停机通宵干啥?修改程序啊。
Tesla的工厂不同于传统生产线,是由大量机械臂来进行生产。
机械臂有个很强的优点,就是只要修改程序,马上就可以进行其他工作和生产。很灵活。
但是也有个致命的问题。就是工厂里大量依赖程序员进行机械臂动作的编程。如果一只机械臂的程序有问题,或者要进行一些修改。都要停机,重新上传程序,重新调试。然后再恢复生产。
如果你刚才认真看了我讲的强化学习的原理,这里我不用点破大家也理解了马老板为啥要投资OpenAI。
因为制约生产速度的瓶颈就是给机械臂编程的人。
玩魔方的小手将来会变成自动生产汽车的协作机械手。
而强化学习的主要作用就是【自己找到最优解】
所以一辆汽车4万个零件,先装哪个后装哪个?怎么组装最高效。这些人类设计的组装流程可能会被全部推翻。
经过计算甚至很可能会出现一种结果,先装座椅靠背垫才是最优解。
在这么庞大的效率计算能力面前,人类帮不上啥忙。
2049
既然机器可以自行推理出4万个零件的汽车如何组装。那他们能自动推理出大豆和棉花怎么种植最高效吗?
大家知道中国传统的农历其实就是一种经过数据训练收敛的数据模型。
我们根据每年播种的时间和收成情况,把播种的时间进行收敛到一个最合适的时间。
可是一本农历数据能在气候,温度,湿度,作物跨度如此大的全国通用吗?
一些外来新品种比如榴莲呢?
在可预见的未来比如2049年,大规模机械农场完全由机械臂来进行农作物的种植。
那你会说,如果全用机器来种植,万一有个数据缺陷,所有的植物不就都嗝屁了么?
 为了人工神经网络的【基因多样性】,除了大片的【生产型田地】 为了人工神经网络的【基因多样性】,除了大片的【生产型田地】 还会有一片用来尝试求解的【试验田】,里面的各项参数会人为的调整,甚至模拟糟糕的天气,降水,和温度。以培育出能适应不同恶劣条件的品种。保证田地的环境适应性。
我们把这些模拟的干扰项叫做【Neo】【墨菲斯】,而这片试验田叫【锡安】
 我们亲手制造的孩子--强化学习,正把大豆和棉花奴役在他们的Matrix中。 我们亲手制造的孩子--强化学习,正把大豆和棉花奴役在他们的Matrix中。 黑客帝国中的人类被机器奴役成人肉电池 黑客帝国中的人类被机器奴役成人肉电池 我一直很想有机会可以请教一下大豆&棉花种植方面的专家。有朋友可以介绍?
最后一个彩蛋:因为强化学习的运算需要依赖环境数据。尤其是和硬件结合的时候,需要环境的3D空间数据。还记得有个玩意叫TOF么? |